使用OpenCV/python进行双目测距
步骤:
- 立体标定(Matlab 单双目相机标定+畸变校正)
- 应用标定数据
- 转换成深度图
立体标定在另一篇文章已有教程这里直接从应用标定数据开始
我们所用到的主要函数stereoRectify以及initUndistortRectifyMap
Python: cv.StereoRectify(cameraMatrix1, cameraMatrix2, distCoeffs1, distCoeffs2, imageSize, R, T, R1, R2, P1, P2, Q=None, flags=CV_CALIB_ZERO_DISPARITY, alpha=-1, newImageSize=(0, 0)) -> (roi1, roi2)
| 参数: |
|
|---|
|
1 2 3 4 |
#进行立体更正,输出R1, R2, P1, P2, Q, validPixROI1, validPixROI2 R1, R2, P1, P2, Q, validPixROI1, validPixROI2 = cv2.stereoRectify(left_camera_matrix, left_distortion, right_camera_matrix, right_distortion, size, R, T) |
Python: cv2.initUndistortRectifyMap(cameraMatrix, distCoeffs, R, newCameraMatrix, size, m1type[, map1[, map2]]) → map1, map2
| 参数: |
|
|---|
 。
。![(k_1,k_2,p_1,p_2 [,k_3 [,k_4,k_5,k_6]])](https://docs.opencv.org/2.4/_images/math/94288b7709d10a7ddf286e33db0074512bda0411.png) 4,5或8个元素的失真系数的输入向量 。如果向量为NULL /空,则假定零失真系数。
4,5或8个元素的失真系数的输入向量 。如果向量为NULL /空,则假定零失真系数。 。
。
|
1 2 |
# 计算更正map,输出map1,map2 left_map1, left_map2 = cv2.initUndistortRectifyMap(left_camera_matrix, left_distortion, R1, P1, size, cv2.CV_16SC2) |
根据以上代码我们只要输入对应参数即可,打开我们在Matlab保存的*.mat文件:
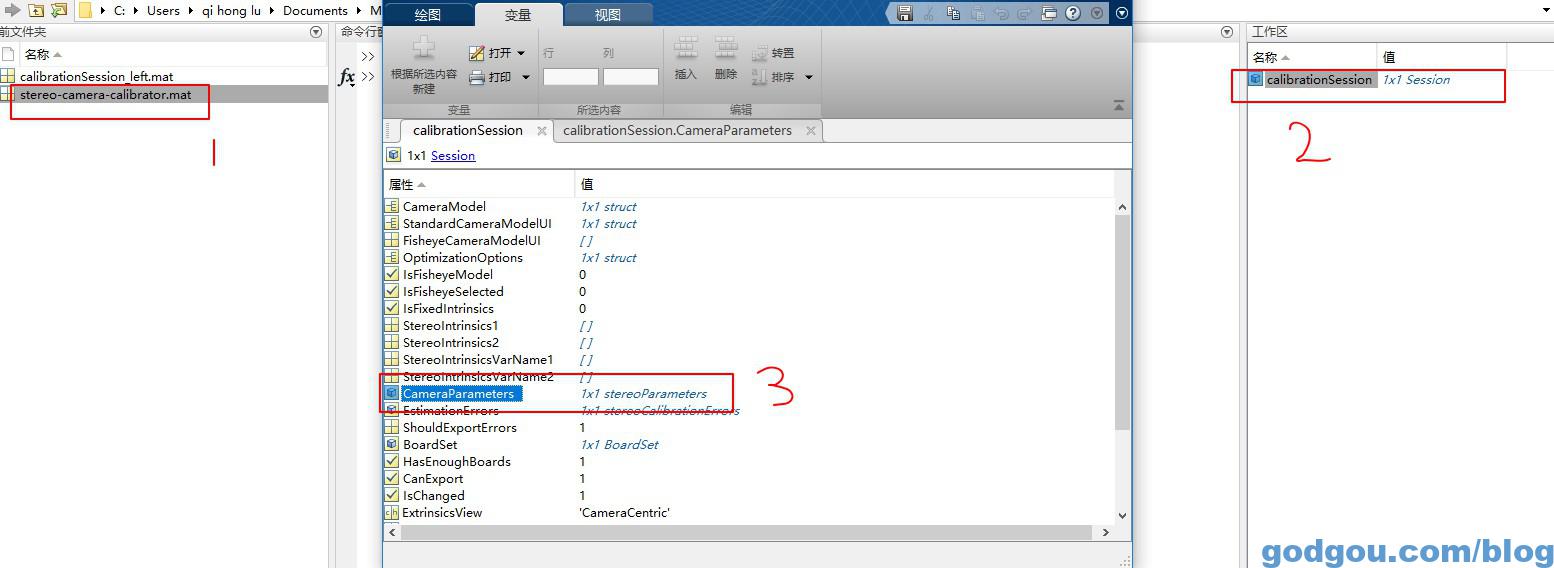
双击打开“CameraParameters ”得到如下文件:
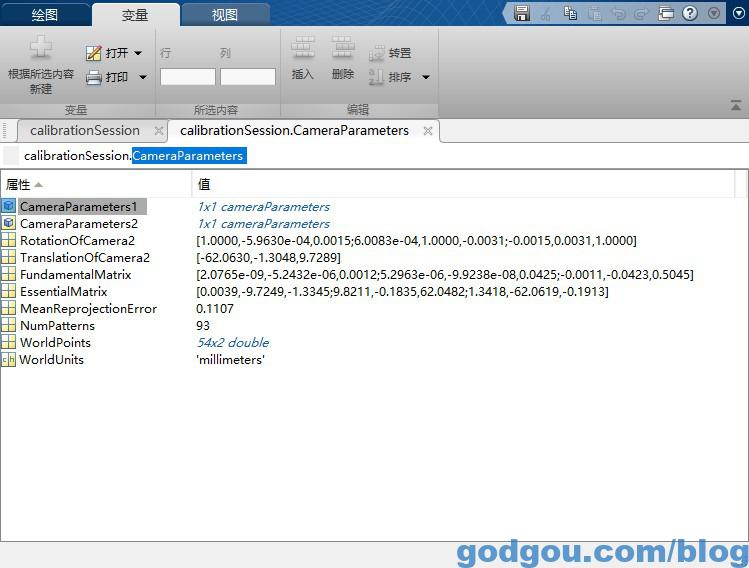
CameraParameters1一个相机矩阵就在里面拿
CameraParameters2第一个相机矩阵就在里面拿
RotationOfCamera2第二个相机相对于第一个相机的旋转矩阵3*3
如果你得到的是3*1向量可用如下代码转换为3*3距阵:
可以直接采用opencv中的Rodrigues函数实现,函数原型cv2.Rodrigues:
void Rodrigues( InputArray src, OutputArray dst, OutputArray jacobian = noArray() );
1
参数:
输入src:旋转向量(3*1或者1*3)或者旋转矩阵(3*3);
输出dst:旋转矩阵(3*3)或者旋转向量(3*1或者1*3);
输出jacobin:可选项,输出雅克比矩阵(3*9或者9*3),输入数组对输出数组的偏导数
TranslationOfCamera2摄像机坐标系之间的平移向量3*1
双击打开“CameraParameters1”如下图:
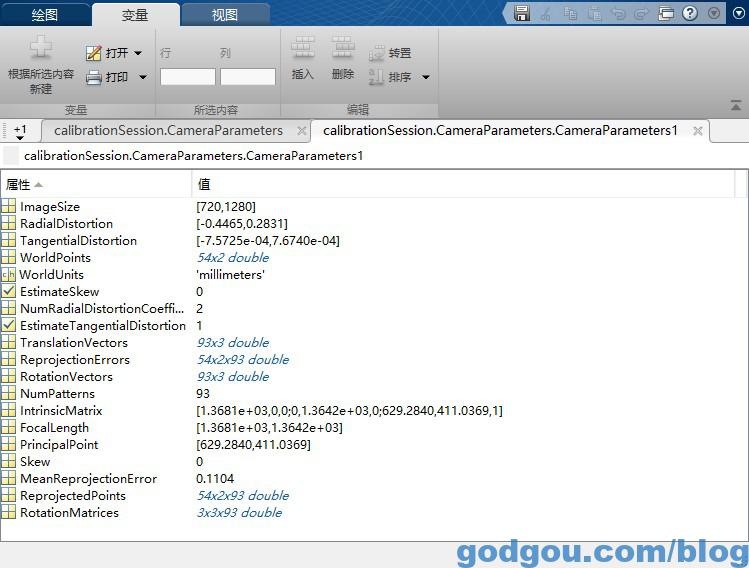
我们可以得到:
图像大小:ImageSize
失真(畸变)参数:RadialDistortion对应k1,k2,k3设置为0了所以上面只显示两个参数,TangentialDistortion对应p1,p2
在OpenCV中的畸变系数的排列(这点一定要注意k1,k2,p1,p2,k3),千万不要以为k是连着的。
相机内参:IntrinsicMatrix,注意这个和OpenCV中是转置的关系,注意不要搞错
我们标定出来的参数对应[fx,0,0;0,fy,0;cx,cy,1]但这里我们需要的参数格式为[fx,0,cx;0,fy,cy;0,0,1]
应用参数:
新建“mycamera_configs.py”文件完整代码如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
# filename: mycamera_configs.py import cv2 import numpy as np #左相机内参矩阵IntrinsicMatrix #我们标定出来的参数对应[fx,0,0;0,fy,0;cx,cy,1] #但这里我们需要的参数格式为[fx,0,cx;0,fy,cy;0,0,1] left_camera_matrix = np.array([[1368.08598037417,0,629.283962301935], [0,1364.21597496711,411.036913391610], [0,0,1]]) #对应Matlab所得左i相机畸变参数 #RadialDistortion对应k1,k2,k3设置为0了,TangentialDistortion对应p1,p2 #OpenCV中的畸变系数的排列(k1,k2,p1,p2,k3) left_distortion = np.array([[-0.446498661369017,0.283116732525898,-0.000757252869225108,0.000767395447611844,0]]) #右相机参数可参考左相机的参数说明 right_camera_matrix = np.array([[1359.56577875582,0,606.509608290797], [0,1355.41443758203,392.485774667712], [0,0,1]]) right_distortion = np.array([[-0.442504595471953,0.259266651090121,-0.00306717312928014,0.000441212354907385,0]]) #第二个相机相对于第一个相机的旋转矩阵3*3 R = np.array([[0.999998718034737,-5.963007514036611e-04,0.001486053261511],[6.008323672759144e-04,0.999995165640009,-0.003050851861062],[-0.001484226852138,0.003051740818875,0.999994241957735]]) #如果你得到的是3*1向量可用如下代码转换为3*3距阵 #R = cv2.Rodrigues(om)[0] # 平移关系向量3*1 T = np.array([-62.062988907275820,-1.304803650621560,9.728880983556905]) size = (1280,720) # 图像尺寸 # 进行立体更正 R1, R2, P1, P2, Q, validPixROI1, validPixROI2 = cv2.stereoRectify(left_camera_matrix, left_distortion, right_camera_matrix, right_distortion, size, R, T) # 计算更正map left_map1, left_map2 = cv2.initUndistortRectifyMap(left_camera_matrix, left_distortion, R1, P1, size, cv2.CV_16SC2) right_map1, right_map2 = cv2.initUndistortRectifyMap(right_camera_matrix, right_distortion, R2, P2, size, cv2.CV_16SC2) |
转换深度图:
Python: cv2.reprojectImageTo3D(视差,Q [,_3dImage [,handleMissingValues [,ddepth ] ] ] ) →_3dImage
-
参数: - disparity – 输入单通道8位无符号,16位带符号,32位带符号或32位浮点差异图像。
- _3dImage – 输出与3相同大小的3通道浮点图像
disparity。每个元素_3dImage(x,y)包含(x,y)从视差图计算的点的3D坐标 。 - Q –
 可以获得的透视变换矩阵
可以获得的透视变换矩阵 stereoRectify()。 - handleMissingValues – 指示函数是否应处理缺失值(即未计算差异的点)。如果
handleMissingValues=true,那么具有与异常值相对应的最小视差的像素(参见StereoBM::operator())被转换为具有非常大的Z值(当前设置为10000)的3D点。 - ddepth – 可选的输出数组深度。如果是
-1,输出图像将具有CV_32F深度。ddepth也可以设置为CV_16S,CV_32S或CV_32F。
该函数将单通道视差图转换为表示3D表面的3通道图像。也就是说,对于每个像素(x,y)和相应的差异d=disparity(x,y),它计算:
![\ begin {array} {l} [X \; Y \; Z \; W] ^ T = \ texttt {Q} * [x \; y \; \ texttt {disparity}(x,y)\; 1] ^ T \\ \ texttt {\ _ 3dImage}(x,y)=(X / W,\; Y / W,\; Z / W)\ end {array}](https://docs.opencv.org/2.4/_images/math/febeb096c7cbbd6472eaad73947edddd8483708a.png)
矩阵Q可以是任意 矩阵(例如,由计算的矩阵 stereoRectify())。要将稀疏的点集{(x,y,d),…}重新投影到3D空间,请使用 perspectiveTransform()。
完整代码如下:
用鼠标点击即可输出当前点世界坐标,世界坐标系的原点是左摄像头凸透镜的光心
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 |
import numpy as np import cv2 import mycamera_configs cv2.namedWindow("left") cv2.namedWindow("right") cv2.namedWindow("depth") cv2.moveWindow("left", 0, 0) cv2.moveWindow("right", 600, 0) cv2.createTrackbar("num", "depth", 0, 10, lambda x: None) cv2.createTrackbar("blockSize", "depth", 5, 255, lambda x: None) camera = cv2.VideoCapture(1) #设置分辨率 camera.set(cv2.CAP_PROP_FRAME_WIDTH,2560) camera.set(cv2.CAP_PROP_FRAME_HEIGHT,720) # 添加点击事件,打印当前点的距离 def callbackFunc(e, x, y, f, p): if e == cv2.EVENT_LBUTTONDOWN: print (str(threeD[y][x])) cv2.setMouseCallback("depth", callbackFunc, None) while True: ret1, frame = camera.read() #裁剪坐标为[y0:y1, x0:x1] frame1 = frame[0:720, 0:1280] frame2 = frame[0:720, 1280:2560] if not ret1: break # 根据更正map对图片进行重构 img1_rectified = cv2.remap(frame1, mycamera_configs.left_map1, mycamera_configs.left_map2, cv2.INTER_LINEAR) img2_rectified = cv2.remap(frame2, mycamera_configs.right_map1, mycamera_configs.right_map2, cv2.INTER_LINEAR) # 将图片置为灰度图,为StereoBM作准备 imgL = cv2.cvtColor(img1_rectified, cv2.COLOR_BGR2GRAY) imgR = cv2.cvtColor(img2_rectified, cv2.COLOR_BGR2GRAY) # 两个trackbar用来调节不同的参数查看效果 num = cv2.getTrackbarPos("num", "depth") blockSize = cv2.getTrackbarPos("blockSize", "depth") if blockSize % 2 == 0: blockSize += 1 if blockSize < 5: blockSize = 5 # 根据Block Maching方法生成差异图(opencv里也提供了SGBM/Semi-Global Block Matching算法,有兴趣可以试试) stereo = cv2.StereoBM_create(numDisparities=16*num, blockSize=blockSize) disparity = stereo.compute(imgL, imgR) disp = cv2.normalize(disparity, disparity, alpha=0, beta=255, norm_type=cv2.NORM_MINMAX, dtype=cv2.CV_8U) # 将图片扩展至3d空间中,其z方向的值则为当前的距离 threeD = cv2.reprojectImageTo3D(disparity.astype(np.float32)/16., mycamera_configs.Q) #cv2.imshow("left", frame1) #cv2.imshow("right", frame2) cv2.imshow("left", img1_rectified) cv2.imshow("right", img2_rectified) cv2.imshow("depth", disp) key = cv2.waitKey(1) if key == ord("q"): break elif key == ord("s"): cv2.imwrite("./snapshot/BM_left.jpg", imgL) cv2.imwrite("./snapshot/BM_right.jpg", imgR) cv2.imwrite("./snapshot/BM_depth.jpg", disp) camera.release() cv2.destroyAllWindows() |



")




